
Why Small Language Models Will Eat Most Agentic Workloads in 2026 (And What That Means For You)
Hybrid is the future!

The frontier-cloud narrative says agentic AI gets better as models get bigger. NVIDIA’s own research disagrees. Production deployments back it up. The economics are 10-30x in favor of small models. Here’s the case for why the next 18 months belong to SLMs running locally and exactly what that means for your stack, your career, and your AI spending.
Let me start with a claim that’s going to feel wrong to most people.
Most agentic AI work in 2026 doesn’t need a frontier model. It needs a small, fast, well-orchestrated model and the people who figure this out early will save dramatic amounts of money, latency, and complexity while building systems that are arguably better.
I’ve been holding this thesis privately for a few months. Last week, someone asked in a LinkedIn comment thread what task convinced me local was good enough to stop reaching for the cloud. I gave a short answer about Hermes Agent and orchestration quality. But the longer version of that answer is bigger than a comment it’s a position about where agentic AI is actually heading.
This article is the full argument. It includes the research backing (it’s strong), the production evidence (it’s striking), the honest counter-cases (there are real ones), and a practical guide for what to do about it whether you’re a developer, founder, or knowledge worker.
By the end you’ll have a clear view on whether the SLM thesis applies to your situation. For most readers, it will. For some, it won’t. The article makes both cases honestly.
What “SLM” actually means
Let’s get definitions out of the way. A Small Language Model (SLM) is typically defined as under 10 billion parameters. Examples that matter in 2026: Phi-4-mini (3.8B), Gemma 4 4B, Qwen 3.5 in its 4B-9B variants, Mistral Small 3 7B, SmolLM3 3B, Llama 3.3 8B.
These models run on consumer hardware. A 7B model in Q4 quantization needs about 6GB of memory. A 4B model fits comfortably on a phone. A 27B model the upper end of what most people mean by “small” runs smoothly on a MacBook Pro.
By contrast, frontier cloud LLMs are typically 70B+ parameters (and the actual frontier GPT-5, Claude Opus 4.7, Gemini Ultra sit somewhere around 200B-2T total parameters, with the exact numbers undisclosed).
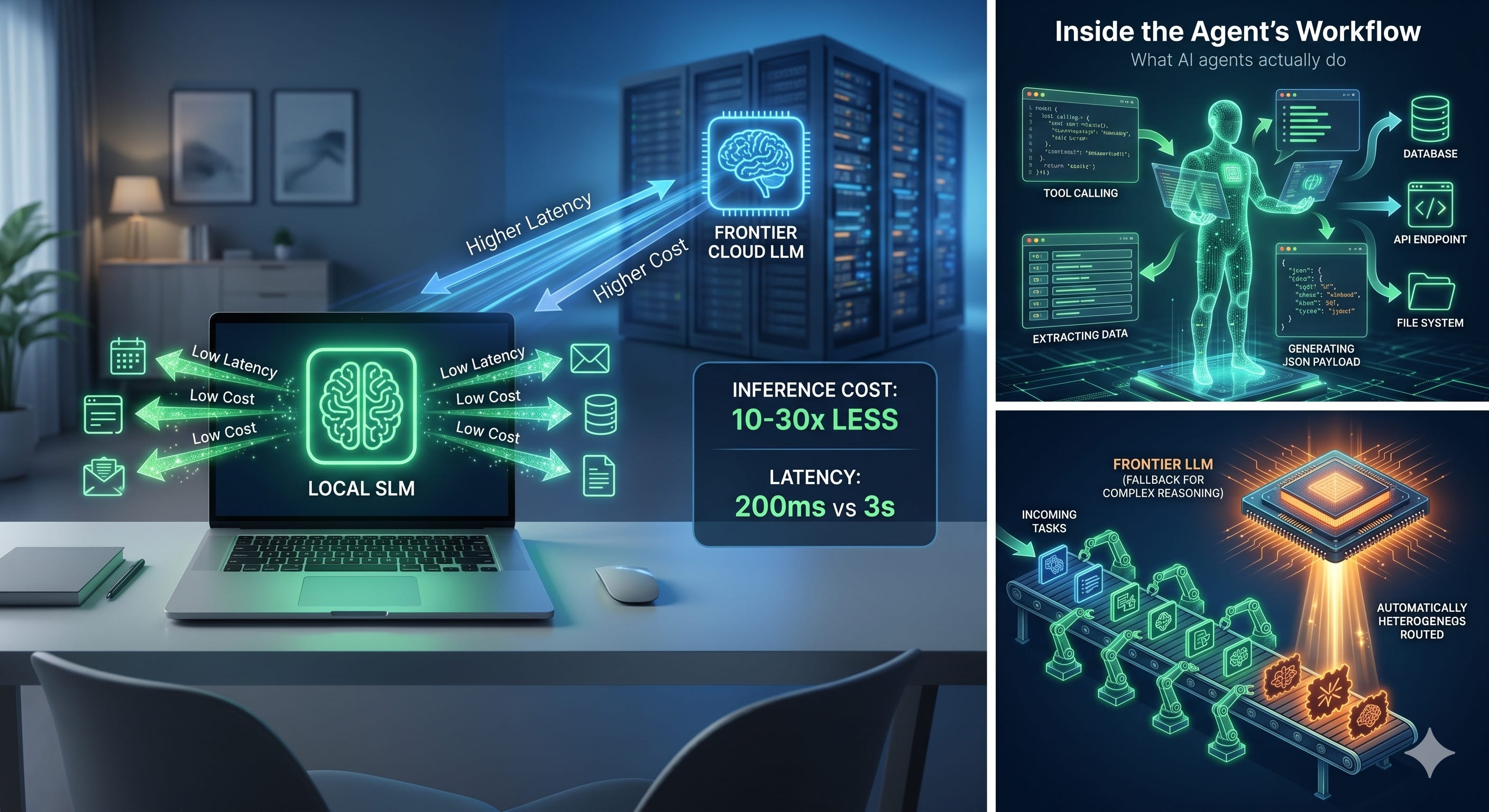
The argument isn’t “SLMs are smarter than LLMs.” They aren’t. The argument is something more specific: for the work that AI agents actually do, raw intelligence matters less than orchestration quality, latency, cost, and reliability of structured output. Once you understand what agents actually do all day, the case for SLMs becomes obvious.
What AI agents actually do (the part nobody examines closely)
Spend a week watching an AI agent’s actual work. Not the demos the actual production traces.
What do you find?
You find that 90% of agent invocations are doing what looks remarkably mundane:
Reading a request and deciding which tool to call
Generating a function call payload in valid JSON
Classifying a piece of text into a category
Extracting structured data from unstructured input
Routing a sub-task to a more specialized component
Producing a short, well-formatted response
These are not reasoning-heavy tasks. They don’t require knowledge of every novel since 1850. They don’t need to understand quantum mechanics. They need to be fast, cheap, reliable about output format, and consistent about tool calling.
That’s what SLMs are good at. That’s actually what SLMs are better at than LLMs in many cases, because their narrower training makes them more predictable about structured output.
The 10% of agent invocations that genuinely need frontier capability novel reasoning, long-context synthesis, creative composition, the hardest problems are exactly the cases where you’d want to call out to a large model. And here’s the key insight: you can do that. Hybrid architectures where SLMs handle the bulk of work and LLMs handle the edge cases are not exotic. They’re becoming standard.
NVIDIA’s own research paper “Small Language Models are the Future of Agentic AI” by Belcak et al., published in 2025 argued this point with formal rigor and the weight of the company most invested in selling large-model infrastructure publishing against its own business interest. That’s not a small detail. The biggest GPU vendor in the world published research saying you don’t need their flagship GPUs for most agentic work. That should make you pay attention.
The economics are not subtle
Let me give you the numbers, because the gap is not “20% cheaper.” It’s an order of magnitude.
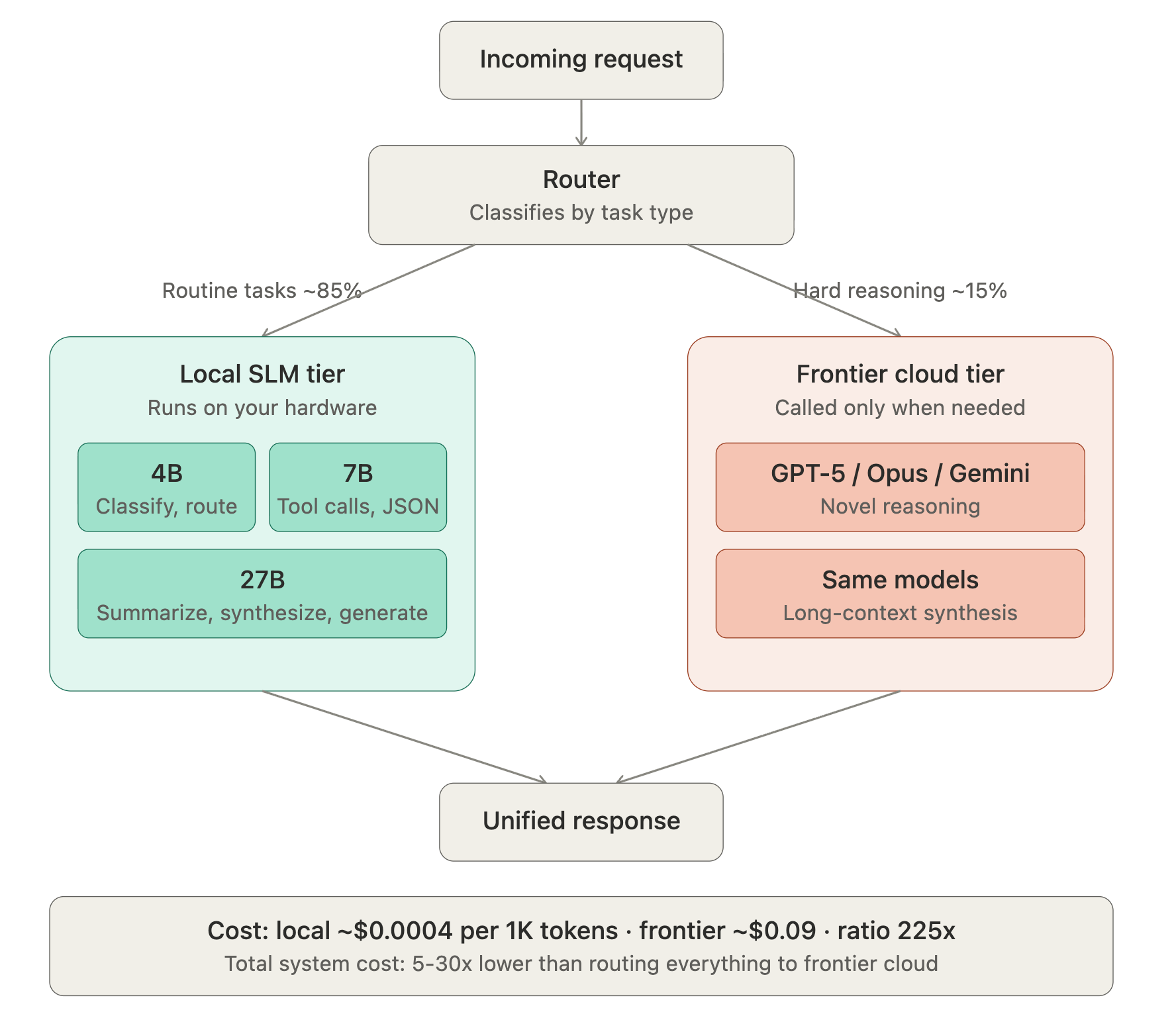
Inference cost. Running a 7B SLM is roughly 10-30x cheaper than running a 70-175B LLM per token. Mistral 7B inference costs around $0.0004 per 1,000 tokens. GPT-4-class models cost roughly $0.09 per 1,000 tokens for comparable requests. That’s a 225x ratio at the extreme end. Even comparing carefully same task, similar performance after fine-tuning production deployments report 5-29x cost reductions when replacing proprietary LLMs with open-source SLMs (University of Michigan study, replicated across multiple enterprises).
Latency. SLM inference on local hardware typically takes 100-300ms. Cloud LLM round-trips average 2-5 seconds end-to-end. For interactive agentic workflows, the difference is qualitative, not quantitative. A 200ms agent feels responsive. A 3-second agent feels broken. You can’t build certain product categories voice assistants, real-time classification, fraud detection on frontier-cloud latency, regardless of how smart the model is.
Energy. A 7B parameter model uses roughly 1-3% of the energy per inference of a 175B model. At enterprise scale, this stops being a sustainability talking point and starts being a real operational line item.
Fine-tuning economics. Fine-tuning a frontier LLM takes weeks and millions of dollars. Fine-tuning an SLM takes hours on a single GPU and is feasible for almost any team. That difference compounds when you need domain-specific behavior and most agentic systems benefit from domain-specific tuning.
The numbers compound in ways most engineering teams don’t fully model:
An agent making 100,000 calls/day on a frontier model: roughly $9,000/day in inference costs alone
Same agent on a fine-tuned 7B SLM: roughly $40/day
Same agent on a self-hosted SLM: roughly $0/day in marginal inference cost (just hardware amortization)
Iterathon documented one production case where a workflow moving from GPT-5 to a fine-tuned 3B SLM dropped monthly costs from $4.2M to under $1,000 a 99.98% reduction. Outlier? Yes. Directional reality? Also yes. The economic asymmetry is that severe.
Why the orchestration argument matters more than the model argument
Here’s the part of the thesis that’s underrated.
The interesting bet I’m making isn’t “small models will catch up to big models in raw capability.” That’s not happening on the timeline I’m describing. Frontier models will keep being smarter than SLMs in absolute terms.
The bet is something different: the bottleneck on agent quality has shifted from model capability to orchestration quality. And orchestration quality is largely independent of model size.
Consider what makes agents fail in production:
They lose track of what they were doing across a long task
They produce malformed JSON that breaks downstream systems
They use the wrong tool when multiple tools could plausibly apply
They hallucinate facts that aren’t grounded in their actual context
They drift away from the user’s actual goal during multi-step work
Notice that none of these failures are primarily about model intelligence. They’re about task decomposition, context management, output validation, and process discipline. A frontier model with bad orchestration fails at all of these. A small model with good orchestration handles most of them well.
This is what frameworks like Hermes Agent, agent-skills (Addy Osmani’s project), and the Specification Skill pattern are addressing. The work is happening at the orchestration layer, not the model layer. Once you accept that, the case for spending 30x on a frontier model for every routine step becomes much weaker.
A specific example from my own work: I run a research agent that decomposes a topic into sub-questions, searches the web, reads sources, synthesizes findings, and produces a structured brief. On the frontier-cloud version, each step is competent but slow and expensive. On a Qwen 3.6 27B local version paired with good orchestration prompts, the output quality is genuinely indistinguishable for the kind of research I actually do. The model isn’t smarter but the system is structured better, and structure does most of the work.
The case against (taking it seriously)
Honest writers acknowledge their counter-cases. Here are the real ones.
The hardest reasoning tasks still favor frontier models. Multi-step mathematical reasoning, novel research questions, work that requires synthesizing across domains in non-obvious ways for these, GPT-5 or Claude Opus 4.7 still outperforms anything in the SLM tier. If your agentic system depends on this kind of work, SLMs are a worse choice for those specific calls.
SLM fine-tuning requires expertise most teams don’t have. Running an SLM out of the box gets you 60-70% of the quality. Getting the last 30% requires data collection, cleaning, and fine-tuning skills that aren’t widespread. Most companies will hit the ceiling of what unfine-tuned SLMs can do and incorrectly conclude SLMs aren’t good enough. The teams that invest in fine-tuning expertise will dramatically out-perform the teams that don’t.
Operational complexity shifts, not disappears. Hosting your own model means owning the deployment, monitoring, scaling, and reliability. Frontier cloud APIs come with operational excellence baked in. If your team can’t run reliable infrastructure, the cost savings of self-hosting evaporate against the cost of outages.
Frontier models keep improving. This isn’t a static comparison. By the time you’ve built an SLM-based system, the next generation of frontier models will be cheaper, faster, and capable of things SLMs can’t do. The “race” isn’t over it just has new dimensions.
The capability gap is not uniform across domains. SLMs are excellent at tool calling and structured output. They’re noticeably worse at creative writing, long-context synthesis, and tasks requiring deep world knowledge. The right model depends on the workload and many real workloads are mixes of these task types.
If any of these counter-cases describe your specific situation, the SLM-first thesis is wrong for you. The thesis is “most” agentic workloads, not “all” agentic workloads. The honest read is that SLMs win the median case and lose specific edge cases.
The hybrid architecture is the actual answer
Once you accept both the bull case and the counter-cases, the obvious conclusion is that production agentic systems should be heterogeneous. NVIDIA’s paper calls this a “Lego-like” architecture: small specialized models handling routine tasks, occasional calls to frontier models for the genuinely hard problems.
In practice, this looks like:
Classification and routing 4B model running locally, sub-200ms response
Tool calling and structured output generation 7B model fine-tuned on your domain
Standard summarization and synthesis 13B or 27B model, still local
Hard reasoning, novel problem-solving, long-context work call out to frontier API only when needed
The economic structure of this is dramatically different from the “use GPT-5 for everything” pattern most teams default to. The frontier API call becomes the exception, not the default. Costs drop 70-95% with quality kept comparable for the majority of work.
This is what production teams are quietly building right now. The companies cutting their AI infrastructure costs by 75% aren’t switching to a cheaper LLM provider. They’re rearchitecting their agentic systems to route work to the right model size for each task. The pattern is real, replicable, and being adopted faster than most coverage suggests.
What this means for you
The implications differ depending on who you are. Here’s the practical read for each audience.
If you’re a developer: Start building with SLMs as your default and frontier APIs as your escalation path, not the reverse. Get fluent with LM Studio, Ollama, or vLLM. Learn to fine-tune at least one SLM end-to-end (Qwen, Phi, or Gemma are the most accessible). The teams hiring most aggressively in 2027 will be the ones rearchitecting their agent stacks for hybrid SLM-LLM use and they’ll pay a premium for engineers who already know how.
If you’re a founder: Your AI infrastructure costs are probably 3-10x higher than they need to be. The capital saved by an SLM-first rearchitecture is real and immediately deployable to other priorities. The other side: if your product’s defensibility depends on “we use the best AI,” that pitch is weakening. Most users can’t tell the difference between a well-orchestrated 7B model and GPT-5 for the use cases that matter to them.
If you’re an operator or PM: The “AI line item” in your budget is about to get scrutinized differently. The question is shifting from “do we have enough AI budget” to “are we using the right models for each task.” If you can articulate which workloads need frontier capability and which don’t, you’ll have outsized influence over technology spending decisions.
If you’re a knowledge worker using AI personally: This is where the thesis lands most directly. Tools like Hermes Agent paired with Qwen 3.6 27B can handle the agentic work you’ve been paying $20-30/month for cloud subscriptions to do. Not all of it but most of it. The economic case for running your own local agent stack got noticeably stronger this quarter.
If you’re an investor in AI infrastructure: The “more compute = better AI” thesis isn’t wrong, but the application of that thesis is shifting. The next layer of value capture is in orchestration, fine-tuning infrastructure, and on-device deployment not in providing access to the largest possible model. The companies that miss this transition will be the next decade’s “owned the rail but missed the train” story.
What I’d actually do in the next 90 days
If this thesis convinces you, here’s a practical sequence. Don’t try to do everything at once.
Week 1-2: Install LM Studio or Ollama on your local machine. Run a 7B and a 27B model. Get a feel for the latency, the quality, the workflow. This is the foundation for everything else.
Week 3-4: Pick one workflow you currently do with a frontier cloud model. Rebuild it using a local SLM, with no expectation of perfect quality. Notice where it falls short those are the cases that genuinely need a frontier model. Notice where it’s indistinguishable those are the cases where you’ve been overpaying.
Week 5-8: Build a hybrid architecture for that workflow. Local SLM for 80-90% of calls, frontier API for the 10-20% that need it. Measure the cost reduction. If it’s not 5-10x, your task decomposition isn’t yet optimized.
Week 9-12: Pick one more workflow. Repeat. By the end of the quarter, you’ll have direct, personal evidence of which work genuinely needs frontier capability and which work doesn’t. This is information you cannot get from articles like this one. You have to build it yourself.
By the end of the quarter you’ll either be running mostly local with occasional cloud calls or you’ll know specifically why your workload is the exception. Both are valuable outcomes.
The bigger picture
The dominant AI narrative for the last three years has been: AI gets better as models get bigger, and bigger means cloud. The implication baked into that narrative is that AI infrastructure is a centralizing force most of it will live in a small number of frontier data centers, with everyone else calling out to APIs.
The SLM thesis is the first credible challenge to that centralization. The compute moves to your laptop, your phone, your desktop, the edge devices in your warehouse, the workstation under your desk. The cost structure shifts from “per request” to “amortized over hardware you already own.” The data sovereignty story goes from “you have to trust the API provider” to “the data never leaves your machine.”
This doesn’t kill frontier AI. The hardest reasoning will keep happening in data centers. The truly novel work will still get cloud-scale resources. The frontier will keep advancing.
But the median agent invocation in 2027 will probably run locally. The median knowledge worker will probably own at least one piece of AI infrastructure. The median company will probably run a hybrid stack, not a pure cloud one. The economics are too lopsided for any other equilibrium to hold.
I’m staking the position publicly: by the end of 2026, “small models orchestrated well, with cloud fallback for the hard cases” will be the standard architecture for production agentic systems. The teams that build for this now will be ahead. The teams that don’t will be spending 5-10x more than they need to.
If I’m wrong, I’ll write the correction in 18 months. But the evidence I’m reading right now NVIDIA’s own research, the production cost numbers, the orchestration framework maturation, the personal experiments I’ve run all point the same direction.
The future of agentic AI is small, local, and orchestrated. Most coverage hasn’t caught up yet. That’s the opportunity.
For more practitioner-level writing on agentic AI and the downloadable Claude Project bundles and skills designed for the hybrid SLM-LLM future subscribe to The Agentic Review. New articles weekly. Paid subscribers get the full library.
This is such a well written article and thought provoking too. I really wanted to learn and implement these. Do we have any step by step guidelines? Any video tutorials. There is so much information that it’s confusing from where to start.